Go学习笔记(实验楼)
[TOC]
一、Go语言介绍
Go语言的特性
并发编程*
Go 语言引入了 goroutine,它是 Go 实现快速高效的并发编程的关键。通过调用 go 关键字,我们就可以让函数以 goroutine 的方式进行运行,也就是以协程为单位进行运行。
协程比线程更加的轻量级,也更节省系统资源,这使得我们可以创建大量的 goroutine,从而进行轻松且高质量的并发编程。同时,goroutine 内部采用管道
channel进行消息传递,从而实现共享内存。在第五章我们还将对 Go 并发编程进行详细的讲解。
错误处理
Go 语言中的错误处理的哲学和 C 语言一样,函数通过返回错误类型 (error) 或者 bool 类型(不需要区分多种错误状态时)表明函数的执行结果,调用检查返回的错误类型值是否是 nil 来判断调用结果。并引入了 defer 关键字用于标准的错误处理流程,并提供了内置函数 panic、recover 完成异常的抛出与捕捉。
垃圾回收
Go 语言自带垃圾自动回收的功能,让 Go 语言不需要 delete 关键字,也不需要 free() 来释放内存。因此开发者无需考虑何时需要释放之前分配的内存的问题,系统会自动帮我们判断,并在适当的时候进行垃圾处理。垃圾自动回收是 Go 语言的一个特点,也是一大亮点。
多返回值
Go 语言和 Python 一样也支持函数的多返回值功能,这个特性让开发者可以从原来用各种比较别扭的方式返回多个值得痛苦中解脱出来,不需要为了一次返回多个值而专门定义一个结构体。并且每个返回值都有自己的名字,开发者还可以选择具体需要返回的值,只需要使用下划线作为占位符来丢掉不要的返回值即可。
匿名函数
Go 语言支持常规的匿名函数和闭包,开发者可以随意对匿名函数变量进行传递和调用,下面就是一个匿名函数样例:
1 | |
Go语言可以做什么
Go 语言是谷歌发布的第二款开源编程语言。专门针对多处理器系统应用程序的编程进行了优化,使用 Go 编译的程序可以媲美 C 或 C++ 代码的速度,而且更加安全、支持并行进程。
Go 的目标是希望提升现有编程语言对程序库等依赖性 (dependency) 的管理,这些软件元素会被应用程序反复调用。由于存在并行编程模式,因此也被设计用来解决多处理器的任务。目前,已经有很多公司开始使用 Go 语言开发自己的服务,甚至完全转向 Go 开发,也诞生了很多基于 Go 的服务和应用,比如 Dokcer、k8s 等,现在我们看下,有哪些大公司在用 Go 语言了。
Google 对 Go 寄予厚望。旗下 App Engine 和其他部分产品已经开始使用 Go 语言来编写。作为开发 Go 语言的公司,当仁不让。
Facebook 也在用 GO,还专门在 GitHub 上建立了一个开源组织 Facebookgo,大家可以通过 GitHub 访问查看 Facebook 开源的项目,比如著名的——平滑升级的 grace。
此外,百度、阿里都在招 GO。京东云消息推送系统、云存储以及京东商城等都有使用 Go 做开发。
360 对 Golang 的使用主要是开源的日志搜索系统 Poseidon。而且,360 直播在招聘 Golang 开发工程师。
小米对 Golang 的支持,莫过于运维监控系统的开源,也就是 open-falcon 。此外,小米互娱、小米商城、小米视频、小米生态链等团队都在使用 Golang。
二、Go语言基础
常量
常量使用关键字 const 声明,下面有几个例子:
1 | |
Go 的常量定义可以限定常量类型,但不是必需的。如果定义常量时没有指定类型,那么该常量就是无类型常量,也叫字面常量。
当需要设置多个常量的时候,不必重复使用 const 关键字,可以使用以下语法:
1 | |
Go 语言还预定义了这些常量:true、false、iota。
iota 是一个可以被编译器修改的常量,在 const 关键字出现时被重置为 0,在下一个 const 出现之前,每出现一次 iota,其所代表的数字自动加 1。下面通过一个例子讲解 iota 的用法:
1 | |
操作符
算术运算符
+:相加;-:相减;*:相乘;/:相除;%:求余;++:自增;--:自减;
其中,
++与--不能用于赋值表达式, 如:count2 := count++;并且在 Go 语言中,不存在如:++count表达式。
关系运算符
==:检查两个值是否相等,如果相等返回true,否则返回false;!=:检查两个值是否不相等,如果不相等返回true,否则返回false;>:检查左边值是否大于右边值,如果是返回true,否则返回false;<:检查左边值是否小于右边值,如果是返回true,否则返回false;>=:检查左边值是否大于等于右边值,如果是返回true,否则返回false;<=:检查左边值是否小于等于右边值,如果是返回true,否则返回false;
逻辑运算符
&&:逻辑AND运算符。如果两边的操作数都是true,则条件为true,否则为false;||:逻辑OR运算符。如果两边的操作数有一个true,则条件为true,否则为false;!:逻辑NOT运算符。如果条件为true,则逻辑NOT添加为true,否则为false;
位运算符
&:按位与运算符。其功能是参与运算的两个数的二进制按位对齐,当对应位都为 1 时,才返回 1;|:按位或运算符。其功能是参与运算的两个数的二进制按位对齐,当对应位中只要有一位是 1,就返回 1;^:按位异或运算符。其是参与运算的两个数的二进制按位对齐,当对应位有一位是 1,就返回 1;如果对应两位都是 1 或 0,就返回 0;<<:左移运算符。其功能是将数值的二进制所有位向左移动指定的位数;>>:右移运算符。其功能是将数值的二进制所有位向右移动指定的位数;
赋值运算法
=:简单的赋值运算符,将一个表达式的值赋给一个左值;+=:相加后再赋值;-=:相减后再赋值;*=:相乘后再赋值;/=:相除后再赋值;%=:取余后再赋值;&=:按位与后赋值;|=:按位或后赋值;^=:按位异或后赋值;<<=:左位移后赋值;>>=:右位移后赋值;
*和&
&是取地址符号 , 即取得某个变量的地址 , 如 :&a*是指针运算符 , 可以表示一个变量是指针类型 , 也可以表示一个指针变量所指向的存储单元 , 也就是这个地址所存储的值 .
变量
变量是所有语言最基本和最重要的组成部分。Go 语言引入了关键字 var 对变量进行声明,也可以使用 := 来对变量直接进行初始化,Go 编译器会自动推导出该变量的类型,这大大的方便了开发者的工作。但是需要注意的是 := 左侧的变量不能是已经被声明过的,否则会导致编译器错误。
以下是 Go 声明和初始化变量的各种方法:
1 | |
多重赋值
Go 语言提供了大多数语言不支持的多重赋值,这使得变量的交换变得十分简单。下面通过一个例子来了解 Go 语言的多重赋值:
1 | |
这样的方式可以一行代码实现变量的交换,明显的减少代码的行数,而不需要像 C/C++ 那样引入一个中间变量。
数据类型*
整型
Go 语言提供了 11 种整型,如下列表所示。
| 类型 | 说明 |
|---|---|
byte |
等同于 uint8 |
int |
依赖于不同平台下的实现,可以是 int32 或者 int64 |
int8 |
[-128, 127] |
int16 |
[-32768, 32767] |
int32 |
[-2147483648, 2147483647] |
int64 |
[-9223372036854775808, 9223372036854775807] |
rune |
等同于 int32 |
uint |
依赖于不同平台下的实现,可以是 uint32 或者 uint64 |
uint8 |
[0, 255] |
uint16 |
[0, 65535] |
uint32 |
[0, 4294967295] |
uint64 |
[0, 18446744073709551615] |
uintptr |
一个可以恰好容纳指针值的无符号整型(对 32 位平台是 uint32, 对 64 位平台是 uint64) |
在 C 语言中我们可以通过 sizeof 操作符查看类型的字节长度,在 Go 语言中可以通过 unsafe.Sizeof 函数进行,创建源文件 type_length.go,输入以下代码:
1 | |
以上代码中,首先声明了目前的源文件属于 main 包,然后导入了 fmt 和 unsafe 包,fmt 包用于格式化字符串,unsafe 包含了用于获取 Go 语言类型信息的方法。然后在 main() 函数中,我们分别声明了几种类型的整型变量,并通过 unsafe.Sizeof 方法获取该类型的字节长度。最后我们通过以下方法运行 type_length.go,同时打印出了输出:
1 | |
浮点型
Go 语言提供了两种浮点类型和两种复数类型,具体如下:
| 类型 | 说明 |
|---|---|
| float32 | ±3.402 823 466 385 288 598 117 041 834 845 169 254 40x1038 计算精度大概是小数点后 7 个十进制数 |
| float64 | ±1.797 693 134 862 315 708 145 274 237 317 043 567 981x1038 计算精度大概是小数点后 15 个十进制数 |
| complex32 | 复数,实部和虚部都是 float32 |
| complex64 | 复数,实部和虚部都是 float64 |
布尔类型
Go 语言提供了内置的布尔值 true 和false。Go 语言支持标准的逻辑和比较操作,这些操作的结果都是布尔值。值得注意的地方是可以通过 !b 的方式反转变量 b 的真假。需要注意的是布尔类型不能接受其他类型的赋值,不支持自动或强制的类型转换。实例代码如下:
1 | |
字符串
Go 语言中的字符串是 UTF-8 字符的一个序列(当字符为 ASCII 码时则占用 1 个字节,其它字符根据需要占用 2-4 个字节)。UTF-8 是被广泛使用的编码格式,是文本文件的标准编码,其它包括 XML 和 JSON 在内,也都使用该编码。由于该编码对占用字节长度的不定性,Go 中的字符串也可能根据需要占用 1 至 4 个字节,这与其它语言如 C++、Java 或者 Python 不同。Go 这样做的好处是不仅减少了内存和硬盘空间占用,同时也不用像其它语言那样需要对使用 UTF-8 字符集的文本进行编码和解码。
Go 语言中字符串的可以使用双引号 (") 或者反引号 (``) 来创建。双引号用来创建可解析的字符串字面量,所谓可解析的是指字符串中的一些符号可以被格式化为其他内容,如\n` 在在输出时候会被格式化成换行符,如果需要按照原始字符输出必须进行转义。而反引号创建的字符串原始是什么样,那输出还是什么,不需要进行任何转义。以下是几个例子:
1 | |
Go 语言中的部分转义字符如下表所示:
| 转义字符 | 含义 |
|---|---|
\\ |
表示反斜线 |
\' |
单引号 |
\" |
双引号 |
\n |
换行符 |
\uhhhh |
4 个 16 进制数字给定的 Unicode 字符 |
在 Go 语言中单个字符可以使用单引号 (') 来创建。之前的课程中,我们有学习过 rune 类型,它等同于 int32,在 Go 语言中,一个单一的字符可以用一个单一的 rune 来表示。这也是容易理解的,因为 Go 语言的字符串是 UTF-8 编码,其底层使用 4 个字节表示,也就是 32 bit。
在 Go 语言中,字符串支持切片操作,但是需要注意的是如果字符串都是由 ASCII 字符组成,那可以随便使用切片进行操作,但是如果字符串中包含其他非 ASCII 字符,直接使用切片获取想要的单个字符时需要十分小心,因为对字符串直接使用切片时是通过字节进行索引的,但是非 ASCII 字符在内存中可能不是由一个字节组成。如果想对字符串中字符依次访问,可以使用 range 操作符。另外获取字符串的长度可能有两种含义,一种是指获取字符串的字节长度,一种是指获取字符串的字符数量。字符串支持以下操作:
| 语法 | 描述 |
|---|---|
s += t |
将字符串 t 追加到 s 末尾 |
s + t |
将字符串 s 和 t 级联 |
s[n] |
从字符串 s 中索引位置为 n 处的原始字节 |
s[n:m] |
从位置 n 到位置 m-1 处取得的字符(字节)串 |
s[n:] |
从位置 n 到位置 len(s)-1 处取得的字符(字节)串 |
s[:m] |
从位置 0 到位置 m-1 处取得的字符(字节)串 |
len(s) |
字符串 s 中的字节数 |
len([]rune(s)) |
字符串 s 中字符的个数,可以使用更快的方法 utf8.RuneCountInString() |
[]rune(s) |
将字符串 s 转换为一个 unicode 值组成的串 |
string(chars) |
chars 类型是 []rune 或者 []int32, 将之转换为字符串 |
[]byte(s) |
无副本的将字符串 s 转换为一个原始的字节的切片数组,不保证转换的字节是合法的 UTF-8 编码字节 |
让我们尝试一个例子,创建源文件 string_t.go,然后输入以下源代码:
1 | |
然后通过以下方式运行,在这里一起显示了程序的输出:
1 | |
说明:
通过前面的课程我们知道通过 \uhhhh 的方式我们可以通过创建 Unicode 字符。
在以上程序中,首先通过 := 符号创建了变量 t0,其值为 \u6B22\u8FCE\u6765\u5230,是 欢迎来到 中文字符的 unicode 编码,然后以同样的方式创建了变量 t1,其值为 实验楼,然后通过 + 操作符将 t0 和t1 拼接赋值给 t2。然后我们通过 range 操作符号对 unicode 字符串 t2 中的每一个 unicode 字符依次操作,我们这里只是简单的打印出每个字符在 t2 中的位置,每个字符的 unicode 码值,每个字符的字面量,每个字符的十六进制值,以及每个字符的字节长度。
这里我们使用 fmt 包种支持的格式指令,如果读者学习过 C 语言的话就一目了然。接着,我们通过 len 操作符计算出了每个字符串的字节长度。最后,我们使用切片访问了字符串 t2 的第 0-1 个字节,也就是前两个字节,其内容为 E6AC。前面我们说到不能使用切片的方式访问非 ASCII 字符串中的字符,原因在这里一目了然。字符 欢 其底层使用了三个字节表示,内容是 E6ACA2,如果只是简单的使用切片(只取切片中的一项)访问的是不能访问到整个字符的,因为字符的切片是通过字节数来索引的。
格式化字符串
Go 语言标准库中的 fmt 包提供了打印函数将数据以字符串形式输出到控制台,文件,其他满足 io.Writer 接口的值以及其他字符串。目前为止我们使用了 fmt.Printf 和 fmt.Println,对于前者的使用,就像 C 语言中的 printf 函数一样,我们可以提供一些格式化指令,让 Go 语言对输出的字符串进行格式化。同样的我们可以使用一些格式化修饰符,改变格式化指令的输出结果, 如左对齐等。常用的格式化指令如下:
| 格式化指令 | 含义 |
|---|---|
%% |
% 字面量 |
%b |
一个二进制整数,将一个整数格式化为二进制的表达方式 |
%c |
一个 Unicode 的字符 |
%d |
十进制数值 |
%o |
八进制数值 |
%x |
小写的十六进制数值 |
%X |
大写的十六进制数值 |
%U |
一个 Unicode 表示法表示的整形码值,默认是 4 个数字字符 |
%s |
输出以原生的 UTF-8 字节表示的字符,如果 console 不支持 UTF-8 编码,则会输出乱码 |
%t |
以 true 或者 false 的方式输出布尔值 |
%v |
使用默认格式输出值,或者使用类型的 String() 方法输出的自定义值,如果该方法存在的话 |
| %T | 输出值的类型 |
常用的格式化指令修饰符如下:
空白如果输出的数字为负,则在其前面加上一个减号-。如果输出的是整数,则在前面加一个空格。使用%x或者%X格式化指令输出时,会在结果之间添加一个空格。例如fmt.Printf("% X", "实")输出 E5 AE 9E。#%#o输出以0开始的八进制数据。%#x输出以0x开始的十六进制数据。
+让格式化指令在数值前面输出+号或者-号,为字符串输出 ASCII 字符(非 ASCII 字符会被转义),为结构体输出其字段名。-让格式化指令将值向左对齐(默认值为像右对齐)。0让格式指令以数字 0 而非空白进行填充。
让我们练习一下,创建源文件 fmt_t.go,输入以下源码:
1 | |
运行代码,输出如下:
1 | |
字符类型
在 Go 语言中支持两个字符类型,
UTF-8:一个是Byte(实际上是 Unit8 的别名),代表 UTF-8 字符串的单个字节的值;Unicode:另一个是rune,代表单个 Unicode 字符。
处于简化语言的考虑,Go 语言的多数 API 都假设字符串为 UTF-8 编码。尽管 Unicode 字符在标准库中有支持,但实际很少使用。
数组
Go 语言的数组是一个定长的序列,其中的元素类型相同。多维数组可以简单地使用自身为数组的元素来创建。数组的元素使用操作符号 [ ] 来索引,索引从 0 开始,到 len(array)-1 结束。数组使用以下语法创建:
[length]Type[N]Type{value1, value2, ..., valueN}[...]Type{value1, value2, ..., valueN}
如果使用了 ...(省略符)操作符,Go 语言会为我们自动计算数组的长度。在任何情况下,一个数组的长度都是固定的并且不可修改。数组的长度可以使用 len() 函数获得。由于数组的长度是固定的,因此数组的长度和容量都是一样的,因此对于数组而言 cap() 和 len() 函数返回值都是一样的。数组也可以使用和切片一样的语法进行切片,只是其结果为一个切片,而非数组。同样的,数组也可以使用 range 进行索引访问。
切片
一般而言,Go 语言的切片比数组更加灵活,强大而且方便。数组是按值传递的(即是传递的副本),而切片是引用类型,传递切片的成本非常小,而且是不定长的。而且数组是定长的,而切片可以调整长度。创建切片的语法如下:
make([ ]Type, length, capacity)make([ ]Type, length)[ ]Type{}[ ]Type{value1, value2, ..., valueN}
内置函数 make() 用于创建切片、映射和通道。当用于创建一个切片时,它会创建一个隐藏的初始化为零值的数组,然后返回一个引用该隐藏数组的切片。该隐藏的数组与 Go 语言中的所有数组一样,都是固定长度,如果使用第一种语法创建,那么其长度为切片的容量 capacity;如果是第二种语法,那么其长度记为切片的长度 length。一个切片的容量即为隐藏数组的长度,而其长度则为不超过该容量的任意值。另外可以通过内置的函数 append() 来增加切片的容量。切片可以支持以下操作:
我们练习下,创建源文件 slice_array.go,输入以下代码:
1 | |
以上代码中,我们首先创建了一个数组,数组的长度是由 Go 语言自动计算出的(省略号语法),然后通过切片操作从数组 a 中创建了切片 s1,接着我们修改了该切片的第一个位置的数值,然后发现数组 a 中的值也发生了变化。最后我们通过 make() 函数创建了一个切片,该切片的长度和容量分别为 10 和 20,还可以发现 Go 语言将未初始化的项自动赋予零值。运行代码输出如下:
1 | |
包
包是各种类型和函数的集合。在包中,如果标示符(类型名称,函数名称,方法名称)的首字母是大写,那这些标示符是可以被导出的,也就是说可以在包以外直接使用。
$GOPATH :环境变量(指向一个或多个目录),以及其子目录 src 目录的,当我们使用 import 关键字导入包的时候,Go 语言会在 $GOPATH 和 GOROOT 目录中搜索包。
三、Go语言顺序编程
流程控制
Go 语言提供的流程控制语句包括
if、switch、for、goto、select,其中select用于监听channel(通道)在讲解通道的时候再详细介绍。
if 语句
语法:
1 | |
其中 optionalStatement 是可选的表达式,真正决定分支走向的是 booleanExpression1 的值。
for 语句
Go 语言的 for 语句可以遍历数组,切片,映射等类型,也可以用于无限循环。以下是其语法:
1 | |
跳转语句goto
Go 语言中使用 goto 关键字实现跳转。goto 语句的语义非常简单,就是跳转到本函数内的某个标签,例如:
1 | |
switch分支
Go 语言中 switch 分支既可用于常用的分支就像 C 语言中的 switch 一样,也可以用于类型开关,所谓类型开关就是用于判断变量属于什么类型。但是需要注意的是 Go 语言的 switch 语句不会自动贯穿,相反,如果想要贯穿需要添加 fallthrough 语句。表达式开关 switch 的语法如下:
1 | |
下面是个例子:
1 | |
在上面的例子中,switch 后面没有默认的表达式,这个时候 Go 语言默认其值为 True。
在前面我们提到过类型断言,如果我们知道变量的类型就可以使用类型断言,但是当我们知道类型可能是许多类型中的一种时候,我们就可以使用类型开关。其语法如下:
1 | |
说了这么多,让我们进行下练习,创建源文件 switch_t.go,输入以下代码:
1 | |
以上代码中我们首先创建了一个接收任意数量任意类型参数的函数,然后使用 for ... range aSlice 的语法迭代了每一个在切片 items 中的元素,接着使用了 switch 类型开关判断了每一个参数的类型,并打印了其值和类型。程序运行输出如下:
1 | |
函数
Go 语言可以很方便的自定义函数,其中有特殊的函数 main 函数。main 函数必须出现在 main 包里,且只能出现一次。当 Go 程序运行时候会自动调用 main 函数开始整个程序的执行。main 函数不可接收任何参数,也不返回任何结果。
函数的定义
在 Go 语言中,函数的基本组成包括:关键字 func、函数名、参数列表、返回值、函数体和返回语句,这里我们用一个简单的加法函数来对函数的定义进行说明。
1 | |
函数的调用
函数调用非常简单,先将被调用函数所在的包导入,就可以直接使用该函数了。注意需要把包文件夹放到 $GOPATH 目录中,实例如下:
1 | |
函数的多返回值
与 C/C++ 和 JAVA 不同,Go 语言的函数和方法可以有多个返回值,这是 Go 提供的一个优美的特性,示例如下:
1 | |
匿名函数
在 Go 语言中,你可以在代码里随时定义匿名函数,匿名函数由一个不带函数名的函数声明和函数体组成,示例如下:
1 | |
你可以将匿名函数直接赋值给一个变量,也可以直接调用运行,示例如下:
1 | |
类型转换
类型转换
Go 语言提供了一种在不同但相互兼容的类型之间相互转换的方式,这种转换非常有用并且是安全的。但是需要注意的是在数值之间进行转换可能造成其他问题,如精度丢失或者错误的结果。以下是类型转换的语法:
resultOfType := Type(expression)
几个例子:
1 | |
另外在 Go 语言中可以通过 type 关键字声明类型,如 type StringsSlice []string 将 []string(string 类型的切片)声明为 StringSlice 类型。
类型断言
说到类型断言就需要先了解下 Go 语言中的接口。在 Go 语言中接口是一个自定义类型。它声明了一个或者多个方法。任何实现了这些方法的对象(类型)都满足这个接口。
接口是完全抽象的,不能实例化。interface{} 类型表示一个空接口,任何类型都满足空接口。也就是说 interface{} 类型的值可以用于表示任意 Go 语言类型的值。
这里的空接口有点类似于 Python 语言中的 object 实例。既然 interface{} 可以用于表示任意类型,那有的时候我们需要将 interface{} 类型转换为我们需要的类型,这个操作称为类型断言。
一般情况下只有我们希望表达式是某种特定类型的值时才使用类型断言。Go 语言中可以使用以下语法:
resultOfType, boolean := expression.(Type):安全的类型断言。resultOfType := expression.(Type):非安全的类型断言,失败时程序会产生异常。
创建源文件 type_t.go,输入以下源文件:
1 | |
运行程序:
1 | |
错误处理*
错误处理是任何语言都需要考虑到的问题,而 Go 语言在错误处理上解决得更为完善,优雅的错误处理机制是 Go 语言的一大特点。
error
Go 语言引入了一个错误处理的标准模式,即 error 接口,该接口定义如下:
1 | |
对于大多数函数,如果要返回错误,可以将 error 作为多返回值的最后一个:
1 | |
调用时的代码:
1 | |
我们还可以自定义错误类型,创建源文件 error.go,输入以下代码:
1 | |
defer
你可以在 Go 函数中添加多个
defer语句,当函数执行到最后时,这些 defer 语句会按照逆序执行(即最后一个defer语句将最先执行),最后该函数返回。特别是当你在进行一些打开资源的操作时,遇到错误需要提前返回,在返回前你需要关闭相应的资源,不然很容易造成资源泄露等问题。
如下代码所示,我们一般写打开一个资源是这样操作的:
1 | |
如果 defer 后面一条语句干不完清理工作,也可以使用一个匿名函数:
1 | |
注意,defer 语句是在 return 之后执行的,新建源文件 defer.go 输入以下代码:
1 | |
panic 和 recover
panic() 函数用于抛出异常,recover() 函数用于捕获异常,这两个函数的原型如下:
1 | |
当在一个函数中调用 panic() 时,正常的函数执行流程将立即终止,但函数中之前使用 defer 关键字延迟执行的语句将正常展开执行,之后该函数将返回到调用函数,并导致逐层向上执行 panic() 流程,直至所属的 goroutine 中所有正在执行的函数被终止。错误信息将被报告,包括在调用 panic() 函数时传入的参数,这个过程称为错误流程处理。
panic() 接受一个 interface{} 参数,可支持任意类型,例如:
1 | |
在 defer 语句中,可以使用 recover() 终止错误处理流程,这样可以避免异常向上传递,但要注意 recover() 之后,程序不会再回到 panic() 那里,函数仍在 defer 之后返回。新建一个源文件 error1.go,输入以下代码:
1 | |
四、面向对象编程
Go 语言的代码是以包结构来组织的,且如果标示符(变量名,函数名,自定义类型等)
*如果以大写字母开头那么这些标示符是可以导出的,可以在任何导入了定义该标示符的包的包中直接使用。Go 语言中的面向对象和 C++,Java 中的面向对象不同,因为 Go 语言不支持继承,Go 语言只支持组合。
自定义类型及结构体
Go 语言的中结构体
struct与 C++、JAVA 中的类class相似,但 Go 放弃了传统面向对象的诸多特性,只保留了组合。
1 | |
其中,typeName 可以是一个包或者函数内唯一合法的 Go 标示符。typeSpecification 可以是任何内置的类型,一个接口或者是一个结构体。所谓结构体,它的字段是由其他类型或者接口组成。例如我们通过结构体定义了一下类型:
1 | |
以上代码我们通过结构体自定义了类型 ColorPoint,结构体中 color.Color 字段是 Color 包的类型 color,这个字段没有名字,所以被称为匿名的,也是嵌入字段。字段 x 和 y 是有变量名的,所以被称为具名字段。假如我们创建了类型 ColorPoint 的一个值 point(通过语法:point := ColorPoint{} 创建),那么这些字段可以通过 point.Color、point.x、point.y 访问。其他面向对象语言中的”类 (class)”、”对象 (object)”、”实例 (instance)”在 Go 语言中我们完全避开使用。相反的我们使用”类型 (type)”和其对应的”值”,其中自定义类型的值可以包含方法。
定义了结构体后如何创建并初始化一个对象实例呢?Go 语言支持以下几种方法进行实现:
1 | |
为了更加方便的创建对象,我们一般会使用一个全局函数来完成对象的创建,这和传统的“构造函数”类似。
1 | |
方法
方法是作用在自定义类型上的一类特殊函数,通常自定义类型的值会被传递给该函数,该值可能是以指针或者复制值的形式传递。定义方法和定义函数几乎相同,只是需要在
func关键字和方法名之间必须写上接接受者。例如我们给类型Count定义了以下方法:
2
3
4
5type Count int
func (count *Count) Increment() { *count++ } // 接受者是一个 `Count` 类型的指针
func (count *Count) Decrement() { *count-- }
func (count Count) IsZero() bool { return count == 0 }以上代码中,我们在内置类型
int的基础上定义了自定义类型Count,然后给该类型添加了Increment()、Decrement()和IsZero()方法,其中前两者的接受者为Count类型的指针,后一个方法接收Count类型的值。
Demo:
类型的方法集是指可以被该类型的值调用的所有方法的集合。
一个指向自定义类型的值的指针,它的方法集由该类型定义的所有方法组成,无论这些方法接受的是一个值还是一个指针。如果在指针上调用一个接受值的方法,Go 语言会聪明地将该指针解引用。
一个自定义类型值的方法集合则由该类型定义的接收者为值类型的方法组成,但是不包括那些接收者类型为指针的方法。
其实这些限制 Go 语言帮我们解决的非常好,结果就是我们可以在值类型上调用接收者为指针的方法。假如我们只有一个值,仍然可以调用一个接收者为指针类型的方法,这是因为 Go 语言会自动获取值的地址传递给该方法,前提是该值是可寻址的。
在以上定义的类型 Count 中,*Count 方法集是 Increment(), Decrement() 和 IsZero(),Count 的值的方法集是 IsZero()。但是因为 Count 类型的是可寻址的,所以我们可以使用 Count 的值调用全部的方法。
另外如果结构体的字段也有方法,我们也可以直接通过结构体访问字段中的方法。下面让我们练习下,创建源文件 struct_t.go,输入以下代码:
1 | |
以上代码中,我们创建了 Count 类型,然后在其基础上又创建了结构体类型 Part。我们为 Count 类型定义了 3 个方法,并在 Part 类型中创建了方法 IsZero() 覆盖了其匿名字段 Count 中 IsZero() 方法。但是我们还是可以二次访问到匿名字段中被覆盖的方法。执行代码,输出如下:
1 | |
组合
Go 语言虽然抛弃了继承,但是却提供了一个更加方便的组合特性。相对于继承的编译期确定实现,组合的运行态指定实现,更加灵活。下面通过一段代码来了解组合的基本属性以及它与继承的不同之处。
先定义一个结构体 Base, 并为它添加两个方法 Foo() 和 Bar():
1 | |
上面代码先定义了一个 Base 类,然后定义了一个 Seed 类。Seed 类“继承”了 Base 类的所有成员属性和方法并重写了 Foo() 方法。同时在重写 Foo() 方法时调用了 Base 类的 Foo() 方法和 Bar() 方法。需要注意的是,若此时 Seed 的对象通过 s.Foo() 调用 Foo() 方法时,实际调用的是 Seed 重写过后的 Foo() 方法,而不是基类 Base 的 Foo() 方法,若想调用 Base 类的 Foo() 方法则要使用 s.Base.Foo,而调用没有重写的 Bar() 方法时,使用 s.Bar() 和s.Base.Bar() 效果是一样的。
接口
在 Go 中,接口是一组方法签名。当一个类型为接口中的所有方法提供定义时,它被称为实现该接口。它与 oop 非常相似。接口指定类型应具有的方法,类型决定如何实现这些方法。
接口基础
之所以说 Go 语言的面向对象很灵活,很大一部分原因是由于接口的存在。接口是一个自定义类型,它声明了一个或者多个方法签名,任何实现了这些方法的类型都实现这个接口。infterface{} 类型是声明了空方法集的接口类型。任何一个值都满足 interface{} 类型,也就是说如果一个函数或者方法接收 interface{} 类型的参数,那么任意类型的参数都可以传递给该函数。接口是完全抽象的,不能实例化。接口能存储任何实现了该接口的类型。直接看例子吧,创建源文件 interface_t.go,输入以下代码:
1 | |
接口变量值的类型*
接口类型声明的变量里能存储任何实现了该接口的类型的值。
有的时候我们需要知道这个变量里的值的类型,那么需要怎么做呢?可以使用类型断言,或者是
switch类型判断分支。以下的例子interface_t1.go我们使用了switch类型判断分支。
1 | |
嵌入interface
结构体中可以嵌入匿名字段,其实在接口里也可以再嵌入接口。如果一个 interface1 作为 interface2 的一个嵌入字段,那么 interface2 隐式的包含了 interface1 里的方法。如下例子中,Interface2 包含了 Interface1 的所有方法。
1 | |
五、并发编程
并发与并行
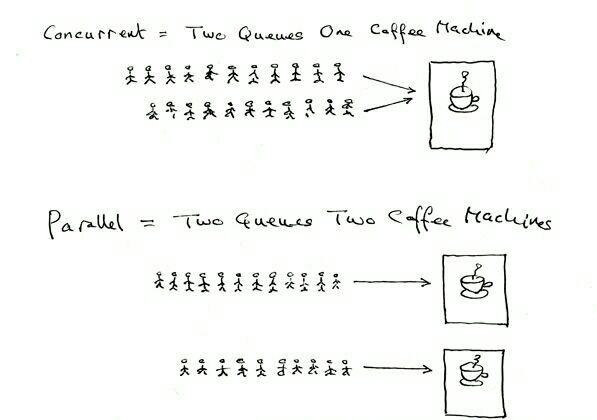
并发指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,通过 CPU 时间片轮转使多个进程快速交替的执行。而并行的关键是你有同时处理多个任务的能力。并发和并行都可以是很多个线程,就看这些线程能不能同时被(多个)CPU 执行,如果可以就说明是并行,而并发是多个线程被(一个)CPU 轮流切换着执行。一个经典且通俗易懂的例子这样解释并发与并行的区别:并发是两个队列,使用一台咖啡机;并行是两个队列,使用两台咖啡机。如果串行,一个队列使用一台咖啡机,那么哪怕前面那个人有事出去了半天,后面的人也只能等着他回来才能去接咖啡,这效率无疑是最低的。图解:
协程
*协程也叫轻量级线程。与传统的进程和线程相比,协程最大的优点就在于其足够“轻”,操作系统可以轻松创建上百万个协程而不会导致系统资源枯竭,而线程和进程通常最多不过近万个。而多数语言在语法层面上是不支持协程的,一般都是通过库的方式进行支持,但库的支持方式和功能不够完善,经常会引发阻塞等一系列问题,而 Go 语言在语法层面上支持协程,也叫
goroutine。这让协程变得非常简单,让轻量级线程的切换管理不再依赖于系统的进程和线程,也不依赖 CPU 的数量。
goroutine*
goroutine 是 Go 语言并行设计的核心。goroutine 是一种比线程更轻量的实现,十几个 goroutine 可能在底层就是几个线程。 不同的是,Golang 在 runtime、系统调用等多方面对 goroutine 调度进行了封装和处理,当遇到长时间执行或者进行系统调用时,会主动把当前 goroutine 的 CPU (P) 转让出去,让其他 goroutine 能被调度并执行,也就是 Golang 从语言层面支持了协程。要使用 goroutine 只需要简单的在需要执行的函数前添加 go 关键字即可。当执行 goroutine 时候,Go 语言立即返回,接着执行剩余的代码,goroutine 不阻塞主线程。下面我们通过一小段代码来讲解 go 的使用:
1 | |
Go 的并发执行就是这么简单,当在一个函数前加上 go 关键字,该函数就会在一个新的 goroutine 中并发执行,当该函数执行完毕时,这个新的 goroutine 也就结束了。不过需要注意的是,如果该函数具有返回值,那么返回值会被丢弃。所以什么时候用 go 还需要酌情考虑。
接着我们通过一个案例来体验一下 Go 的并发到底是怎么样的。新建源文件 goroutine.go,输入以下代码:
1 | |
执行 goroutine.go 文件会发现屏幕上什么都没有,但程序并不会报错,这是什么原因呢?原来当主程序执行到 for 循环时启动了 10 个 goroutine,然后主程序就退出了,而启动的 10 个 goroutine 还没来得及执行 Add() 函数,所以程序不会有任何输出。也就是说主 goroutine 并不会等待其他 goroutine 执行结束。那么如何解决这个问题呢?Go 语言提供的信道(channel)就是专门解决并发通信问题的
channel
channel 是goroutine 之间互相通讯的东西。类似我们 Unix 上的管道(可以在进程间传递消息),用来 goroutine 之间发消息和接收消息。其实,就是在做 goroutine 之间的内存共享。channel 是类型相关的,也就是说一个 channel 只能传递一种类型的值,这个类型需要在 channel 声明时指定。
声明与初始化
channel 的一般声明形式:var chanName chan ElementType。
与普通变量的声明不同的是在类型前面加了 channel 关键字,ElementType 则指定了这个 channel 所能传递的元素类型。示例:
1 | |
初始化一个 channel 也非常简单,直接使用 Go 语言内置的 make() 函数,示例:
1 | |
channel 最频繁的操作就是写入和读取,这两个操作也非常简单,示例:
1 | |
select
select 用于处理异步 IO 问题,它的语法与 switch 非常类似。由 select 开始一个新的选择块,每个选择条件由 case 语句来描述,并且每个 case 语句里必须是一个 channel 操作。它既可以用于 channel 的数据接收,也可以用于 channel 的数据发送。如果 select 的多个分支都满足条件,则会随机的选取其中一个满足条件的分支。
新建源文件 channel.go,输入以下代码:
1 | |
以上代码先初始化两个 channel c1 和 c2,然后开启两个 goroutine 分别往 c1 和 c2 写入数据,再通过 select 监听两个 channel,从中读取数据并输出。
运行结果如下:
1 | |
关于 for select 和 channel 的用法:
select 语句只能与通道联用,它一般由若干个分支组成。每次执行这种语句的时候,一般只有一个分支中的代码会被运行。select 语句的分支分为两种,一种叫做候选分支,另一种叫做默认分支。候选分支总是以关键字 case 开头,后跟一个 case 表达式和一个冒号,然后我们可以从下一行开始写入当分支被选中时需要执行的语句。
由于 select 语句是专为通道而设计的,所以每个 case 表达式中都只能包含操作通道的表达式,比如接收表达式。使用一个接收值可以接收通道里的值,使用两个接收值可以判断通道是否已经关闭了。
对于 select 语句的执行规则如下:
- 每个 case 都必须是一个通信。
- 所有 Channel 表达式都会被求值。
- 所有被发送的表达式都会被求值。
- 如果任意某个通信可以进行,它就执行,其他被忽略。
- 如果有多个 case 都可以运行,Select 会随机公平地选出一个执行。其他不会执行。 否则:
- 如果有 default 子句,则执行该语句。
- 如果没有 default 子句,select 将阻塞,直到某个通信可以运行;Go 不会重新对 Channel 或值进行求值。
注意这里是和 switch 的操作是不一样的,switch 操作中,只要从上到下有一个满足条件了,就会执行相应的那一个 case,select 中,我们是全部计算一遍,然后再从可满足条件的 case 中公平的执行其中一个。这是为了防止有些通道长期得不到执行。
超时机制
通过前面的内容我们了解到,channel 的读写操作非常简单,只需要通过 <- 操作符即可实现,但是 channel 的使用不当却会带来大麻烦。我们先来看之前的一段代码:
1 | |
观察上面三行代码,第 2 行往 channel 内写入了数据,第 3 行从 channel 中读取了数据,如果程序运行正常当然不会出什么问题,可如果第二行数据写入失败,或者 channel 中没有数据,那么第 3 行代码会因为永远无法从 a 中读取到数据而一直处于阻塞状态。相反的,如果 channel 中的数据一直没有被读取,那么写入操作也会一直处于阻塞状态。如果不正确处理这个情况,很可能会导致整个 goroutine 锁死,这就是超时问题。Go 语言没有针对超时提供专门的处理机制,但是我们却可以利用 select 来巧妙地实现超时处理机制,下面看一个示例:
1 | |
这样的方法就可以让程序在等待 1 秒后继续执行,而不会因为 ch 读取等待而导致程序停滞,从而巧妙地实现了超时处理机制,这种方法不仅简单,在实际项目开发中也是非常实用的。
channel 的关闭
channel 的关闭非常简单,使用 Go 语言内置的 close() 函数即可关闭 channel,示例:
1 | |
关闭了 channel 后如何查看 channel 是否关闭成功了呢?很简单,我们可以在读取 channel 时采用多重返回值的方式,示例:
1 | |
通过查看第二个返回值的 bool 值即可判断 channel 是否关闭,若为 false 则表示 channel 被关闭,反之则没有关闭。
六、词频统计综合案例
实现
词频统计的程序逻辑很简单。我们首先会创建一个映射,然后读取文件的每一行,提取单词,然后更新映射中单词所对应的数量即可。
为了演示面向对象和 goroutine 的使用,我们将基础映射类型封装成了一个统计单词频率的包。我们在基础映射类型上创建了类型 WordCound,然后为该类型了实现了关键方法 UpdateFreq() 和 WordFreqCounter(),其中前者会读取一个文件并统计该文件中的所有单词的词频,后者通过 goroutine 实现了并发统计。
其并发逻辑是:对于每一个文件,创建一个 goroutine,在这个 goroutine 内部调用 UpdateFreq() 方法统计对应文件的词频,当统计完成以后会将映射中每一对键值转化为 Pair 结构发送到 results 通道,并在发送完成时候发送一个空结构体的值到 done 通道以表示自己的任务已经完成。由于 map 映射结构不支持并发写操作,所以我们通过 result 通道来保证每次只有一个 goroutine 能更新映射。又因为当所有的 goroutine 结束以后,有可能 results 通道中还有没来得及处理的数据,所以在 WordFreqCounter() 的结尾我们又开启了一个 for 循环处理 results 通道中的剩余数据。说了这么多,我们直接写代码吧。
在 $GOPATH/src/wordcount 目录中创建文件 wordcount.go,输入以下源码:
1 | |
然后在 $GOPATH 目录中创建文件 wordfreq.go,输入以下源码:
1 | |
七、IDE及环境配置
1 | |








